【エイケン1キュウゼッタイホシイクイズ】 英検一級の過去問を分析したら楽して合格できるはず
毎度おなじみ クソアプリ Advent Calendar 2025 1日目の記事でございます。
Advent Calendarを書き始めると今年ももう終わりかぁってなるよね。
作ったものはこちら

はじめに
あー英検一級が欲しいンゴ。できるだけ楽して欲しい。合格証明書をXにアップして己の虚栄心を満たしたい。
せや、英検の過去3回の過去問は公式サイトでPDFで公開されているし、その過去問を分析して頻出単語を作ってWebアプリにしたら100点満点得間違いなし!
それに、DeepSeek-OCRを使ってみたい。単純にOCRの精度も良さそうだ。Apple siliconのMacでもDeepSeek-OCRが動かせるMLX版もあると聞いた。
オレはデータを取ってきて、いい加減に分析して、なんか作るのが大好きなんだ。
忙しい人のための概要
英検一級の過去問 PDFをDLし、DeepSeek-OCR でテキスト化し、Python でそれっぽく処理して頻出語を抽出した。 延べ 27,536 語のうち、CEFR A2 レベルの「やさしい単語」が 6割以上 を占めるという衝撃の事実がわかり、英検一級は難単語だらけではないことが判明した。
頻出単語については 3 回以上出る単語 812 語、10 回以上出る 117 語 を抽出したところ、頻出単語は感覚的にはTOEIC650点の範囲内なことがわかった。「これ覚えたら普通に合格できるのでは?」という気持ちになる。
ターミナル風 Web アプリを作って、Cloudflare 上のにデプロイして誰でも学習できるようにした。 ターミナル風なので仕事してるように見えるはず!もうね、上司も一生懸命難しいことに取り組んでいるはずと勘違いするから高評価!次のボーナスは大幅アップするし英検一級も手に入るはず!!
※ Webアプリで登場する単語は私的利用の範囲を超えないように、分析した単語リストからそれぞれの単語の近しい単語を生成AIに作ってもらったものである
▶ 集計した単語トップ20 表示(クリックで開く)
問題の指示の英文も計測しているのでそういうのに出そうな単語が含まれているが、そんなに難しい単語がないのがわかるね。
※人名のleiterや、複数形の単数に戻す処理でミスっているspecyも含んでいるのはご愛嬌
| 単語 | 頻度 | 日本語訳 |
|---|---|---|
| situation | 42 | 状況、場面 |
| passage | 40 | 文章、通路、経過 |
| german | 37 | ドイツ人、ドイツ語 |
| system | 32 | システム、制度、体系 |
| follow | 31 | 続く、従う |
| cause | 28 | 原因、引き起こす |
| state | 28 | 状態、国家、述べる |
| mongol | 28 | モンゴル人 |
| lead | 27 | 導く、リード、鉛 |
| provide | 27 | 提供する、供給する |
| result | 26 | 結果、結果として生じる |
| leiter | 25 | ライター(人名) |
| create | 25 | 創造する、作り出す |
| ant | 24 | アリ |
| specy | 23 | 種(species) |
| increase | 22 | 増加する、増加 |
| though | 22 | 〜だけれども、しかし |
| task | 22 | 課題、仕事 |
| focus | 21 | 焦点、集中する |
⸻
忙しくない人のための詳細は以下
試験問題のPDF → JPEG → DeepSeek-OCR
英検のサイトからから過去三回の過去問をダウンロードして、それぞれをPDF→JPEGに変換した。
PDF → JPEG
DeepSeek-OCRの本家リポジトリを眺めていると、PDFをそのまま突っ込んだときに、中で勝手に「ページごとの画像」に変換してくれる処理が入っていた。
ただ、手元のApple SliconのMacでDeepSeek-OCRが動かせる MLX版だとを触ってみると、そのPDF→画像の処理が実装されていなかったので、ここは素直に Python で自前で実装した。
JPEG → DeepSeek-OCR で文字起こし DeepSeek-OCRについてうろ覚えで書くと、 DeepSeek社が2025/10ぐらいに発表したモデルで、「テキストを一回画像に変換してから圧縮すれば、LLMの処理コストを大幅に減らせるんじゃない?」っていう発想を実証したもの。従来の10分の1程度のトークン数でいい感じの精度でテキストを復元できたはず。LLMが長文を効率的に扱うための新しいアーキテクチャ
さっき作ったJPEGを DeepSeek-OCR に流して。ページごとにプレーンテキストを出力させた。M2のmacbook airでもでサクサク動いたのが結構驚いた。
テキスト処理
テキスト前処理:日本語を削り、1文1行にする**
DeepSeek-OCRから返ってくるテキストは、当然そのままだとグチャグチャなので、Python で前処理
- 日本語を全部削除
- 英検の問題文には問題の説明などに使われている日本語を削除
- 1文1行に整形
- .?!などで文の終わりを判断して文を区切る
- ただしMr., No., A.M. など.のついた単語は単純に単語扱いにするなどなどノイズの処理
- 各試験ごとに1文1行のテキストファイルにしたあとに1ファイルに結合する
ここまでやると、ようやく「単語の世界」に入れる
単語レベルの集計
1文1行テキストから単語を抜き出したり、ヒストグラムを作ったりしていく。 ここからはpythonのpandasの出番となる。
この状態で CSV に書き出すと、延べ 27,536 語 重複込み・活用形も全部バラバラ
さらにaやan, the, goとか簡単な単語が多数含まれているので「簡単な単語は一旦全部フィルタリングする」作業をした
CEFR A2レベルの簡単な単語をごっそり削る
「簡単な単語ってどこまでを指すんだよ?」問題を解決するために見つけたのが、 Cambridge English の A2 Key and A2 Key for Schools list (August 2025)
このPDFは、Cambridge University Press & Assessment が公式に出している語彙リストでCEFRの A2レベル(初級レベル)の学習者向けで、Cambridge Learner Corpus(4,400万語以上の学習者コーパス) と English Vocabulary Profile をもとに定期的に更新されている
という、なかなか権威性のある単語リスト
このリストに載っている単語は、「A2レベルの学習者でも扱える初歩的なボキャブラリ」とみなしていいだろうと
このPDFファイルも同じようにDeepSeek-OCRで文字起こしして,各単語ごとに1行1単語のテキストにした。このファイルを利用して抽出した単語リストをフィルタリングした。
フィルタリングの結果:6割以上が“やさしい英語”
フィルタリングした結果
27,536語のうちA2語彙リストに載っている単語を全部削除すると、残った単語数は 10,327語。
つまり:
10,327 / 27,536 ≒ 0.375
英検1級のテキストに出てくる文章のうち、 60%以上は A2レベルの「やさしい英語」で構成されている
ということになる。
もちろん、これはのざっくり集計なのだが、英検一級は難単語だらけで文章が構成されれいるわけではないということがわかる。これは希望になる。英検一級が取れそうな気がしてきた。
ヒストグラムを出しつつ、活用をつぶして、3,521 語まで圧縮する
10,327単語から重複を含んでいるのでpandasで単語の頻度をヒストグラムで計算し、ユニークな単語一覧を作った。
ここからさらに、 - “made / making / makes” → “make” - “students” → “student” - “countries” → “country”
のように、活用形・複数形を雑に1つにまとめる処理をした。
ここは真面目に形態素解析をするのではなく、 - -ed, -ing, -s, -es あたりを適当に剥がして - それでもうまくいかないやつはそのまま
という荒い処理をした(この荒いせいでたまに変な単語が混じるけど、まあいいいでしょう)
この処理のあと、ユニークな単語数は 3,521語 にまで圧縮した。
頻度でみるとどうなるか:812語 / 117語の世界
次に、3,521語それぞれの出現頻度をヒストグラム化した。
そのヒストグラムで頻度順に並べた単語リストを見ると、 「英検一級の試験で、“何度も見る顔ぶれ”って実際どのくらいあるの?」がわかる
- 3回以上 出てきた単語だけを抽出 → 812語
- その中でも 10回以上 出てくるもの → 117語
ってことは、3回分の試験で3回以上出てくるって812語覚えたら合格すんじゃない?そうに違いない。もしかしたら10回以上出てくる117語だけでいけんじゃない?
ChatGPT に日本語訳をまとめて書かせる
この 812語が格納されたCSVファイルを 「この単語リストに対して、日本語の意味を1行ずつつけて返して」 と 雑にChatGPT を叩き、自動で「英単語+日本語訳」のCSVを生成した。
これで英検一級の試験で実際に使われた真の頻出単語の単語リストが完成した。これは世間に出回るどんな英検一級対策の単語リストよりもエビデンスがあるはずだ。そうに違いない。
これって妥当なデータ量じゃないだろと難癖をつけたくなっているあなたへ
いやわかってる。過去問3回では足りないことなんぞ。こちとら高等教育を受けたんだ。なめんなよ。一つの長文問題に同じ単語が何度も出てくることもあるんだ。でも、それでも、少なくともこれと同じ作業を5年分やればかなりのものになるはずだろ?
黒い画面でバレずに勉強!ターミナル風単語学習Webアプリ
集めたデータを眺めているだけではつまらないので、 「英検一級の真の頻出単語を、ターミナル風のUIで遊べるWebアプリ」を作った。
前にgo言語で本当にターミナルで単語学習するアプリを作ってみたんだけど、それのセルフオマージュとしてWebアプリでやってみた。
正味な話、このBlogポストで言いたいの、どうやってデータを取ってきたかどう加工したか、その過程で何がわかったかなので、技術スタックをざっくり紹介するに留める
大まかな技術スタック | カテゴリ | 技術名 | | --- | --- | --- | | 言語 | TypeScript | | フレームワーク | React | | ビルドツール | Vite |
デザイン・UI
| カテゴリ | 技術名 | 説明 |
|---|---|---|
| スタイリング | Tailwind CSS | ユーティリティクラスで全部書く派。コンポーネント化すると気持ちよくなれる。 |
| UIライブラリ | shadcn/ui | モダンでいい感じのコンポーネントが揃っている。実は Terminal 風コンポーネントもあったので、「単語を叩き出すコンソール」っぽいUIも試してみた。 |
インフラ
| カテゴリ | 技術名 | 説明 |
|---|---|---|
| デプロイ先 | Cloudflare workers & pages | GitHub に push すると勝手にビルド&デプロイしてくれる、お手軽ホスティング。無料で結構使える |
| バックエンド機能 | Cloudflare Functions | OGP画像生成用のAPIをここに生やしている。SSRっぽいことをちょっとだけやる場所。 |
| データベース | Cloudflare KV | 生成したOGP画像のURLなどをキャッシュするキー・バリューストア。2回目以降の表示が爆速になる。 |
開発ツール
| カテゴリ | 技術名 | 説明 |
|---|---|---|
| リンター/フォーマッター | Biome | ESLint 設定地獄から逃げるために数年前から Biome に移行 |
| OGP生成 | @cloudflare/pages-plugin-vercel-og | Cloudflare 上で、HTML/CSSっぽい記述からOGP画像を生成できるプラグイン。Vercelの OG Image Generation とほぼ同じノリで書ける。 |
Vite + React + TypeScript + Tailwind + shadcn + Biome という、「2025年現在のモダンなフロントエンド開発」構成の作成は、Googleが先日出したエディタのAntigravityでGemini3.0 proに「Vite + React + TypeScript + Tailwind + shadcn + Biome」で環境構築してってぶん投げたらいい感じに作ってくれた。こういう組み合わせでハマると結構なヤックシェービングになるようなものも生成AIのおかげでかなり楽ができるようになった。
データを眺めて見えてきたこと
頻出単語出てくる「MNPってなに?」から考えるノイズ処理の方法
ヒストグラムを見るとmnpというのが6回ぐらい使われていた。こんな単語がったっけと、 元の試験問題を英検一級2024年3回目の試験より回のような文章で出てきた。
Scientists believe that micro- and nanoplastic particles, or MNPs
つまりmnpとは、mnps -> MNPs (micro- and nanoplastic particles) のこと。 これは今回やった英文から単語を抜き出して複数形や、活用系などを原型にするような単純な処理だとすり抜けてしまう。
文頭の単語を大文字から小文字にする処理をするのに全ての単語を小文字化してから処理すると、こんな感じで略語や固有名詞が抜けてしまう。まず固有名詞は頻出単語からは取り除きたい。どうやってやればいいか検討したいところだ。
また動詞の活用形や、単語の複数形、形容詞や副詞の比較級や最上級への活用形なども抜けてしまうのも、spaCyやNLTKを使ってLemmatizerを用いて原型に戻す作業をすればできるはず。
高頻度の単語はそこまで難しくない
3回以上出てくる 812語 を眺めてみると、 - “こんなん絶対ネイティブも使わないって言うような難単語” は全然ない - むしろ、A2レベルを抜けた「中堅どころ」がよく出る - TOEICでいうと650点ぐらいは取れる人ならわかるレベルという印象
つまり、英検1級は、単語そのものの難易度よりも、 “そこそこ難しい単語 + 難解な構成の英文 + 長文理解 + 難単語を文脈から素早く推測” が求められるのではないだろうか?
お前らを ”スピードの向こう側” に連れて行ってやるぜ
はじめに
この記事は、クソアプリ - Qiita Advent Calendar 2024 - Qiitaの7日目の記事です このアドベントカレンダーも今年で10周年で、おめでたい。オレ以外の毎年書いているいかれたメンバーは何人いるのだろうか?
今までの記事のリンク これを数えたらこの記事を入れてクソアプリが13個ある。アドベントカレンダーが10年皆勤賞で参加しているのに、3個多い。どうやら日常でもいらん物を作ってはブログを書いているらしい。1円にもならないというのもかかわらずだ。
さて、遡ること10年以上前、2000年代後半、当時SEだった僕は美容室に勤めていた地元の友人にこんな約束をした。 「いつか自分の美容室をオープンしたらHPをつくってやるよ」
時を経て2020年頃、ついに彼は独立し美容室がオープンした。約束を守る時が来たのだ。
制作費や運用費をもらわない代わりに好き勝手やらせてもらうことした。 また飲食店や美容室のHPは必要な情報にアクセスしやすくするべきだと思っていた。
わかりやすいシンプルなサイトにしてやろうじゃないか。GoogleのSEO対策もしてやろう。
Googleに好かれつつ、シンプルなHPで可能な遊べる余白はなにか?
!?
"スピードの向こう側"だ。
オレが手に入れてやる・・・! "その領域"・・ "スピードの向こう側"を・・!!
今年のクソアプリは、お前らを連れて行ってやるぜ "スピードの向こう側" によォ!!
※注意 この記事は、2000年代のインターネットのノリと週刊マガジン連載されていた"疾風伝説 特攻の拓"(かぜでんせつ ぶっこみのたく) の薄い知識の影響を受けています
作ったもの
道楽で運用している地元の友だちの美容室のHP(隠しページあり)はこちら。
今回は、このHPを"スピードの向こう側へ" 走り抜けた軌跡を紹介していくぜ・・・!
HPのベース
Astroを使って静的サイトをSSGしている。 Astroはコンパイルすることでいらない情報を諸々削除たり圧縮したり表示を早くすることに特化したFW。 またページ内の一部のJavaScriptを遅延ロードして動かせ、Reactに対応している。
UIコンポーネントにTailwindベースのdaisyUIを使用
Prefetchを使うことで、ページ内のリンクをキャッシュして画面遷移時に表示早くするようにしている。
第一世代のデプロイ先Netlify
HPのホスティング先は慣れている Netlify いや
"電脳璃覇威" にデプロイした
パフォーマンスの計測したLighthouseの結果を見てくれ

こいつを見てどう思う?
!?
すごく大きいです100点満点です
Netlifyにホスティングしたキャッシュを使わない場合の表示速度は、トップページで500ms程度
![]()
ここまで十分速度も早い、必要な情報なコンテンツは全部実装しているし、画像もSVGにして容量を下げている。おまけにSEO対策もした。地方都市の美容室のHPにしては十分だ。
だが待ってほしい、今回のテーマは"スピードの向こう側"だ。
スピードの向こう側への旅はまだ始まったばかりだ・・・!!
第二世代のデプロイ先 Cloudflare
"電脳璃覇威"にも弱点がある。日本にCDNサーバのリージョンがないのだ
一番近くてシンガポール
そして通信プロトコルがHTTP/2に対応しているが "HTTP/3" には対応していない
CDNサーバが日本にあって、HTTP/3に対応している、
それでいてNetlify並に開発体験がいい、そして無料枠が大きいところ
そんな "都合" の良いサービスが有るか?あるわけがねェ・・・!
!?
!?
"雲羅宇怒陽炎"
"こいつ"だ・・・!!! ドエレーー ”COOOL”じゃん・・・?
CloudflareのWorkers & PagesにデプロイしてCDNをキャッシュヒットさせた状態で、トップページにアクセスすると。 30ms !!
![]()
もちろんレスポンスヘッダにCache-Controlも追加している、サーバにアクセスせずにディスクキャッシュ利用した場合は 3msを叩き出す。

だが、まだまだ足りない・・!もっとだ・・!もっとスピードの向こう側へ・・・!!
計測!計測!計測

トップページには、お知らせ情報にアクセスしてJsonを取得してカルーセルを表示するReactのパーツがある。
このAPIを高速化していくぜ!!!
お知らせ情報を取得するWebAPIの機能
美容室のブログであるアメブロにあるお知らせ情報だけをスクレイピングしてJSONに変換して返す。
CloudflareのWorkersにTypeScriptでコードを作成してデプロイしている。 このTypeScriptのコードで利用しているFWはHonoを使っている。Cloudflare上で動きルーティングその他速いらしい。 今回の機能のサイズでは速さを実感するほどものではないがFW自体のサイズが小さいので起動時に時間がかかることがないだろう。
WorkersのTypeScriptのコードでデータをキャッシュする方法は下記の3つのサービスでできそうだ。
Cacheは地域のデータセンターで保存されるらしいが、このデータセンターとCDNのエッジサーバで保存されるのだろうか?
KVの方が早いかもしれない。
D1はSQLiteがCDNエッジサーバで動くらしい、とても早そうだ。
一体どれが一番早いのだろうか?わからない。
それでは計測だ!!!
ローカル環境でベンチマークテスト
Workersはローカルで開発できるので、ベンチマーク用のコードをそれぞれ用意した
Cache版の計測用コード(クリックすると展開)
import { Context } from "hono";
export const benchmarkCache = async (c: Context) => {
const cache = caches.default;
const writeStart = performance.now();
for (let i = 0; i < 100; i++) {
const key = `https://example.com/benchmark_key_${i}`;
const value = new Response('benchmark_value');
await cache.put(new Request(key), value);
}
const writeEnd = performance.now();
const readStart = performance.now();
for (let i = 0; i < 100; i++) {
const key = `https://example.com/benchmark_key_${i}`;
const response = await cache.match(new Request(key));
const value = response ? await response.text() : null;
}
const readEnd = performance.now();
const totalWriteDuration = writeEnd - writeStart;
const totalReadDuration = readEnd - readStart;
const avgWriteDuration = totalWriteDuration / 100;
const avgReadDuration = totalReadDuration / 100;
return c.json({ totalWriteDuration, totalReadDuration, avgWriteDuration, avgReadDuration });
};
KV版の計測用コード(クリックすると展開)
import { Context } from "hono";
export const benchmarkKV = async (c: Context) => {
const writeStart = performance.now();
for (let i = 0; i < 100; i++) {
await c.env.kv.put(benchmark_key_${i}, 'benchmark_value');
}
const writeEnd = performance.now();
const readStart = performance.now();
for (let i = 0; i < 100; i++) {
const value = await c.env.kv.get(`benchmark_key_${i}`);
}
const readEnd = performance.now();
const totalWriteDuration = writeEnd - writeStart;
const totalReadDuration = readEnd - readStart;
const avgWriteDuration = totalWriteDuration / 100;
const avgReadDuration = totalReadDuration / 100;
return c.json({ totalWriteDuration, totalReadDuration, avgWriteDuration, avgReadDuration });
};
D1版の計測用コード(クリックすると展開)
import { Context } from "hono";
export const benchmarkD1 = async (c: Context) => {
// テーブルが存在しない場合は作成
await c.env.d1.prepare(
CREATE TABLE IF NOT EXISTS benchmark_table (
key TEXT PRIMARY KEY,
value TEXT
)
).run();
// テーブルをクリア
await c.env.d1.prepare(`DELETE FROM benchmark_table`).run();
const writeStart = performance.now();
for (let i = 0; i < 100; i++) {
await c.env.d1.prepare(`INSERT INTO benchmark_table (key, value) VALUES (?, ?)`)
.bind(`benchmark_key_${i}`, 'benchmark_value')
.run();
}
const writeEnd = performance.now();
const readStart = performance.now();
for (let i = 0; i < 100; i++) {
const result = await c.env.d1.prepare(`SELECT value FROM benchmark_table WHERE key = ?`)
.bind(`benchmark_key_${i}`)
.first();
}
const readEnd = performance.now();
const totalWriteDuration = writeEnd - writeStart;
const totalReadDuration = readEnd - readStart;
const avgWriteDuration = totalWriteDuration / 100;
const avgReadDuration = totalReadDuration / 100;
return c.json({ totalWriteDuration, totalReadDuration, avgWriteDuration, avgReadDuration });
};
上記のベンチマーク用のWorkersのコードをローカルで動かすと書き込みはD1が一番早く、読み込みはKVが一番早い。
| キャッシュ方式 | 合計書き込み時間 (ms) | 合計読み込み時間 (ms) | 平均書き込み時間 (ms) | 平均読み込み時間 (ms) |
|---|---|---|---|---|
| Cache | 95 | 35 | 0.95 | 0.35 |
| KV | 102 | 17 | 1.02 | 0.17 |
| D1 | 71 | 43 | 0.71 | 0.43 |
今回の使い方だとキャッシュいかに早く取り出して返すかが重要なので、読み込み速度を重視してKVを利用するのが良さそうだ。
Cloudflare Workers上で速度を計測
今度は、実際にCloudflareの環境でそれぞれの方式を使ってAPIを実装した。
そのアメブロをスクレイピングしたデータをキャッシュしたものを取り出して返すAPIの速度を比較すると下記のような結果となり、ベンチマークで計測しただけではわからなかった事が判明した。
| キャッシュ方式 | 平均速度 | 備考 |
|---|---|---|
| キャッシュなし | 200ms | |
| Cache | 25ms~50ms | 80-100msと上振れすることも多い |
| KV | 30ms程度 | 少し間をおいて動かすときにアクセスする際にLambda的なのを起動するのか最初だけ500msぐらいかかる |
| D1 | 480ms程度 | キャッシュなしより遅い、KVと同様に起動時は1秒以上かかる |
この結果から、API上のキャッシュは最初の起動が遅いが安定的なKVを利用することとした。 D1が早いことを期待したが少なくとも2024年現在では、今回の使い方ではKVに軍配が上がった。
どこにでもキャッシュを仕掛けろ!
キャッシュはできるだけ近いところに仕掛けるのが効果が高い
でキャッシュするほうが効果てきめんだ。
さぁここまでにCloudflareの利用によって、HTMLや画像など静的なファイルはCDNでキャッシュし、Cache-Controlをレスポンスヘッダーにつけることによってブラウザにキャッシュを利用している。
WebAPIではWorkersにおいてアメブロをスクレイピングしたデータをKVに保存することでキャッシュするようにした。
まだだ、まだまだ行ける。
!?
WebAPIのアクセスをクライアントでキャッシュしたらサーバにアクセスせずに済むんじゃぁないか?
こんな感じでuseEffectに仕込めばWebAPIアクセスもキャッシュ利用してキャンセルできる
const cachedArticles = localStorage.getItem('latestArticles');
const cachedTime = localStorage.getItem('cacheTime');
const now = new Date().getTime();
if (cachedArticles && cachedTime && now - cachedTime < 600000) {
setLatestArticles(JSON.parse(cachedArticles));
setLoading(false);
return;
}
最終的結果
最終的なパフォーマンスを見て見よう

HA☆YA☆SU☆GI☆RU
さぁ各過程で工夫した箇所をもう一度まとめてみよう
| 項目 | 内容 |
|---|---|
| SSG FW | Astro |
| 他ページの先読み | Prefetch |
| プロトコル | HTTP/3 |
| CDNサーバ | 東京リージョン |
| WebAPIの実行 | Cloudflareのエッジサーバ |
| WebAPIのFW | Hono |
| WebAPIのキャッシュ | KVの利用 |
| ブラウザ静的ファイルのキャッシュ | Cache-Controlの利用 |
| ブラウザWebAPIアクセスのキャッシュ | LocalStorageの利用 |
まとめ
いかがだっただろうか?見た目的には取り立てて派手さのないHPでも視線を変えると遊べる余白があることを証明できたのではないだろうか?
高速化の過程を見せることをお前らを"スピードの向こう側"に導くことができたのではないだろうか。
動画内のJYPのパンチラインで学ぶ英語学習サービスを作ってやったぜ

はじめに
今年も懲りずに クソアプリアドベントカレンダー2023 8日目の記事でございます。 9年連続でやっているらしい。継続は力なりとはよく言ったもので、毎年やっていると今年もやらねばという気持ちになるのは不思議なものである。
さてさて、YouTubeで注目を集めたK-Popオーディション番組「A2K」は、JYP Entertainmentが主催し、アメリカでのK-Popアイドルの発掘を目的としている。
番組内でのJYP Entertainmentの代表JY Park(以下JYP)による印象的なパンチラインが英語学習の素晴らしい素材になるだろうと考えて、どうにかしてWebサービスにしてみた。
具体的には、パンチラインが表示される瞬間に現れる大きなテロップを検出し、その出現時刻を自動で収集するシステムを開発した。ある程度の精度でデータを収集することができたので、このデータをもとにWebサービスを作成した。
今回のクソアプリではChatGPTなど生成AIを使ったものが多くなりそうなので、あえて使わない制約と誓約をかけた。 そうそう今年になってHUNTER×HUNTERをまとめて読んだ。特にキメラアント編をまとめて読んだらとても面白かった。面白すぎて思わず大阪まで冨樫義博展を見に行ってTシャツを買ってしまった。
A2Kプロジェクトとは
A2K、つまり「America to Korea」は、アメリカにおけるK-Popアイドルの発掘を目的としたJYP Entertainmentの野心的なプロジェクトである。K-Pop業界全体がグローバル化を目指す中、JYPは「globalization by localization」という独自の戦略を採用している。この戦略の一環として、JYP自らがオーディションの審査を行い、その過程で放たれる数々の魅力的なパンチラインが、オレの心を熱くする。
一番のお気に入りはA2K ep.16 "Korean Boot Camp Begins"のJYPがJYP Entertainmentのアーティストに求める3つTipsを話しているところ youtu.be
A2Kプロジェクト選定の理由
- アメリカのオーディション参加者は自然な英語を話すため、リアルな英語学習の素材として最適である。
- JYP自身も非常に流暢な英語を話すため、彼の発言はリアルな英語表現の学習に有効である(時折韓国語のアクセントも聞こえるが、オレの現在の英語力では十分にきれいな英語である)
- 番組ではJYPのパンチラインが大きなテロップとして画面に表示されるため、視覚的にも捉えやすく、学習しやすい。
- JYPのポジティブでエモーショナルな言葉は、学習を楽しくさせると同時に、英語の表現力を高めるのに役立つのだ。
開発したサービスの特徴
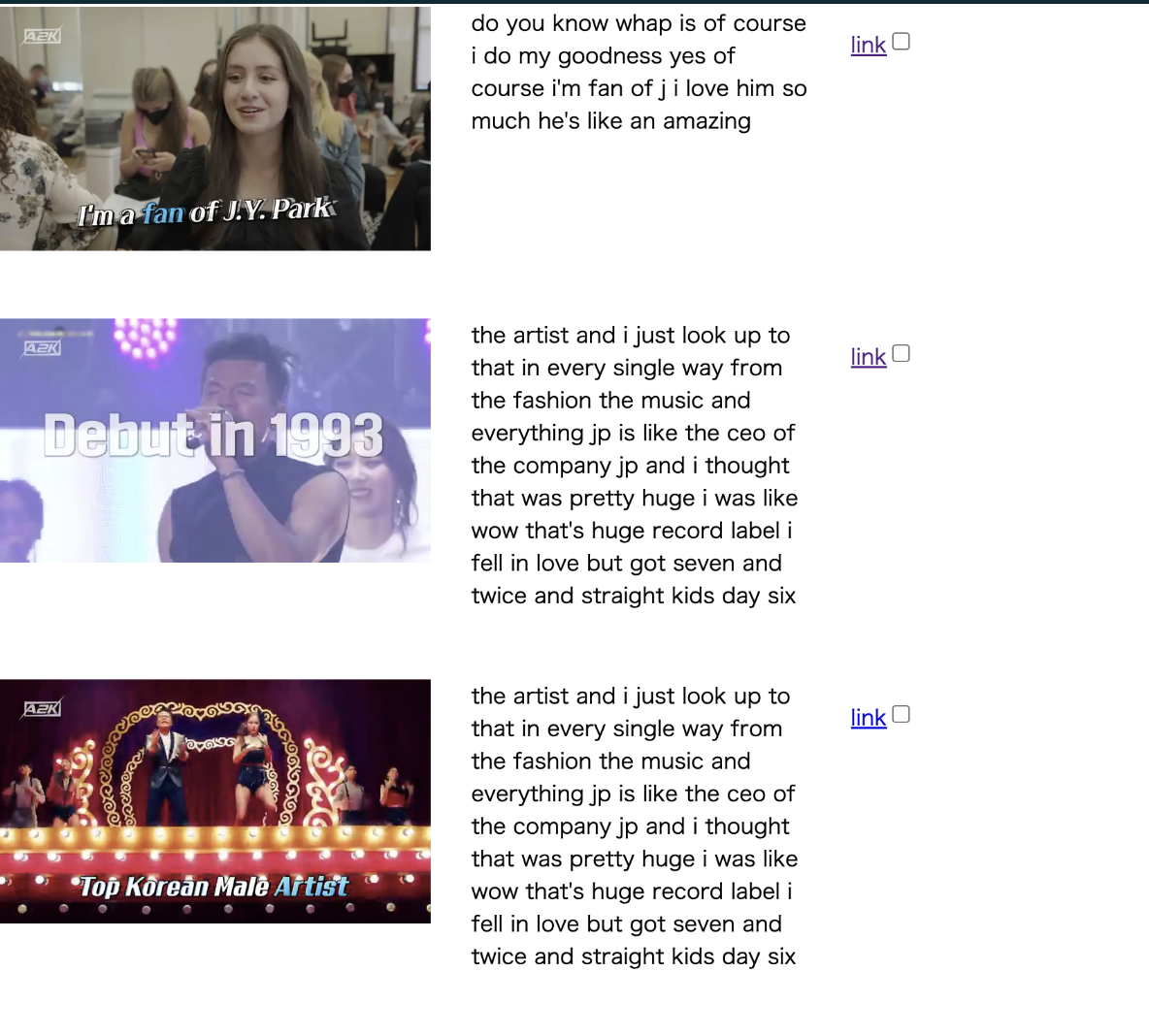
- タイトル: [Punchline English from A2K]
- URL: https://learningenglishfromjyp.pages.dev/
基本の使用方法

- セレクトボックスから視聴したいエピソードを選択する
- 選択後、そのエピソードに含まれるパンチラインの一覧が表で表示される
- 表には以下の情報が含まれる:
- 表の左端にある画像をクリックすることで、対応するパンチラインが含まれる動画の該当部分が再生される。これにより、何度も繰り返し聞いたり、実際にJYPのように発話することで、英語表現を身につけることができる
下記のデモのようにJYPのパンチラインを何度も繰り返し聞いて練習することができるのだ。 youtu.be
詳細な使用方法
- Seekセレクトボックスを使用して、動画の進行や戻りの時間を1秒から20秒の間で設定できる。デフォルト設定は3秒
- 進むボタンや戻るボタンで設定した時間だけ動画を進めたり戻したりすることができる
- ショートカットキーも利用可能で、スペースキーで動画を一時停止・再生、右矢印キーで設定時間だけ進行、左矢印キーで設定時間だけ戻る
システム構成
- 本サービスはTypeScriptとNext.jsを用いて開発された。デプロイはCloudflareのworkers and pagesを利用した
データ収集のための前処理
- YouTubeからの動画ダウンロード
- 動画から音声データとしてmp3ファイルの作成
パンチラインデータ抽出の挑戦
動画の中でパンチラインがいつ表示されているかのデータを探すのには、試行錯誤を必要とした。2秒毎に動画のキャプチャを取り色々処理してみた戦いの結果がこれである。
ChatGPTvやその他OCRのAIライブラリを使えば簡単じゃないかと思うじゃないですか?ところがどっこいそんなに簡単じゃないんだなこれが。AIライブラリだと画像にある文字は取り出すことは精度良く出せるが、動画の中で大きい文字を抽出するはできないのだ(少なくとも2023年12月現在では)
画像の解像度をどんどん下げて、小さいテロップは文字認識できないが、大きいテロップのみ文字認識する境目を探すアプローチを取ってみたが全然上手くいかなかった。
しょうがないので自前でPythonを書いてOCR処理をすることにした。自前でOCR処理をすると認識した文字のサイズを計算することができる。この文字の大きさに基づくしきい値設定した。具体的には認識した文字列のそれぞれの文字サイズを計算してその中央値をしきい値とした。
- ただしOCRの精度は色々工夫したがあまり良くなくて例えばこんな変な文字列を取得してしまうのだ。
(hieinw That won Dawe fo perfor ree | ben oe 4 ; ji - なので、「OCRで文字列を認識した + 認識した文字列が一定以上大きい」 がパンチラインが表示されているキャプチャであるという作りにした。
具体的な例を見ていこう、下記のような小さい文字のテロップを避けたい。そしてずっと出てるA2Kという文字列も無視するように細かい調整をしている。

そして、このようなデカいテロップの文字列があるのを探して、動画内内の何分何秒目であるかを記録して次の工程に進めているのだ。

データ収集後の後処理
- Speach to Text APIを用いて動画の音声のmp3から文字起こししSRT形式で保存
- Flaskを使用して開発された手動チェックするUIを作成
- 文字起こしをしたSRTファイルとキャプチャ画像の照合しCSVファイルの作成
- 英語の文字起をした内容を、GCPの翻訳APIにかけて日本語に翻訳をCSVファイルに追加
- このA2KのYoutubeの動画には、自動翻訳の英語と、翻訳された日本語字幕があるのだが、このデータを検証した結果、タイムスタンプが一対一で対応していないので却下した
まとめ
本サービスは、JYPのパンチラインを活用し、英語学習を支援することを目的としている。A2Kオーディション番組から得られたデータを基に、英語の表現力を効果的に高めることが可能である。本サービスを通じて、英語学習に新たな一歩を踏み出す機会を提供する。