おしゃれ用語が難しくて読めない!そんな悩みを解決 Goodbye OSHARE terms

(おしゃれ人間のイメージ図、平気でハットをかぶり丸めネガネかける)
毎度おなじみクソアプリアドベントカレンダー1日目の記事でございます(皆勤賞) qiita.com
みんなー!今年も役に立たないものを作ったよ!!
おしゃれ用語が難しすぎて読めない
ファッション系のウェブサイトを見ると用語がわからなすぎて全然頭に入らない。マテリアルなど無駄に横文字にする行為や、プチプラ、マストバイアイテムなど独特の和製英語も我々の認知能力に負荷を掛ける。
ファッションサイトの文章とは例えばこんな感じだ。
ファッションの流行はミリタリー&スポーツがアップトレンド。軍物モチーフのジャケットに蛍光フーディーを合わせた旬のミックススタイルの手元には、トーンの近いカーキの「オリジナル・キャンパー」がふさわしい。アクティブでタフな雰囲気に「オリジナル・キャンパー」が同調する。ミリタリーウオッチらしいドーム型のプラスティック風防やナイロンストラップによる軽快な着用感があって、シンプルな文字盤で時間が見やすいのもうれしい。ロープライスなのも僕らの味方だ。
出典: https://www.mensnonno.jp/post/48379/?cx_top=news&shm-vp=3
ちょっと何言ってるかわからない
いや、全然わからないわけじゃないんだけどね、日本語だしね。でもねただただ疲れるんだ。カタカナ語と固有名詞は判断付くようにしたい。
そこでChrome拡張機能を作ってファッション用語の辞書を作ってどんなサイトにも適用できるようにした。
今回作ったもの
先の文章を今回作ったChrome拡張を適用するとこんな感じになる
ファッションの流行は軍用の&スポーツがアップ流行。軍物主題のジャケットに蛍光パーカーを合わせた旬の異なる服装を混ぜた服装服装の手元には、色調の近いカーキの「オリジナル・キャンパー」がふさわしい。アクティブでタフな雰囲気に「オリジナル・キャンパー」が同調する。ミリタリーウオッチらしいドーム型のプラスティック風防やナイロン吊り革による軽快な着用感があって、シンプルな文字盤で時間が見やすいのもうれしい。低いです価格なのも僕らの味方だ。
これでだいぶ読みやすくなった。なったよね? なったに違いない!!
デモ
動かすとこんな感じでファッション用語がわかりやすい言葉に置き換わっていく。
ソースコードはこちら github.com
このソースコード内のchrome_extensionディレクトリを chrome://extensions から読み込むと利用できる
さて、どうやって作ろうか?
さてファッション用語の辞書から対応する言葉を置き換えるとは言っても、辞書はどこにもない。 この辞書をどうやって作ったか、また文字列を置き換えた際にそれぞれのサイトのボタンなど押した際についている動作を失わないようにした工夫を記載していく。
ファッション用語辞書を作る
無い辞書をどうやって作るか、工程は3つ
ファッションサイトをスクレイピング
各サイトから記事のページのリンクをかき集めるにはWeb Scraper を使った。このツールで各サイトの一覧に表示されているリンクを取得してCSV保存した。このツールのおかげで自前でコードを書かずにベースとなるファッションサイトの記事を集められた。
男性向けファッションメディア2つ、女性向けファッションメディア2つの計4メディアから収集
総ページ数は 4792 + 2303 + 700 + 3000 = 10795 ページ
カタカナ語かき集めてそのカタカナ語の頻度を集計
Pythonでスクレイピングと集計処理をした。大まかな処理は以下
- 各サイトのHTMLを取得、正規表現で2文字以上のカタカナの文字列の抜き出してリストする
- カタカナ語の合成語は一般的な日本語では無いので普通の形態素解析では分割できないので諦めた
- カタカナ語のリストからpandas.DataFrameを使って頻度を集計
- 2回以上出てきたカタカナ語が24170個存在していた
- 頻度の高すぎる、低すぎるカタカナ語をフィルタリング
集計結果を元に翻訳して辞書を作成
さて3905個もある用語を一個一個翻訳してられないので、こちらもGoogle Spread sheetを使って自動化した。
日本語から英語、英語から日本語に再翻訳してカタカナ語をわかりやすい言葉に
例えばトラウザーというおしゃれ用語がある。これを、日英、英日に翻訳すると
トラウザーを日本語から英語に翻訳するとTrousers
Trousersを英語から日本語に翻訳するとズボン
このようにトラウザーをズボンとわかりやすい言葉に置き換えることができるのだ
Google Spread sheetにはGOOGLETRANSLATEという関数があって下記のように各セルを翻訳することができるのだ
=GOOGLETRANSLATE(A5,"ja","en") =GOOGLETRANSLATE(B5,"en","ja")
また、もとの値と再翻訳した値が同じかどうか判断するのにEXACT関数を使って判別するようにした =EXACT(A5, C5)
この処理によってこのようなおしゃれ用語をわかり易い言葉に置き換えられた
デコルテ → (日英翻訳)→ Neckline → (英日翻訳) → ネックライン
フーディ → (日英翻訳)→ Hoody → (英日翻訳) → パーカー
とは言っても再翻訳して変な翻訳になっているものと再翻訳しても同じだったものはどう処理するか?
再翻訳大作戦で全部いい感じにおしゃれ用語をわかり易い言葉に置き換えられるかと思ったが、そうは問屋が卸さない。どうしたかというと根性で自力で一個一個訳した。これは結構へこたれそうになった。いやへこたれた。数字でいうと436個でへこたれたようだ。
再翻訳してもうまく行かないパターン3つ
手動翻訳を強いられたのは3つのパターンだった。
●再翻訳してもおしゃれ用語から脱せない
ボトムス → (日英翻訳)→ Bottoms → (英日翻訳) → ボトムス → (手動翻訳)→ズボン
再翻訳してもボトムスに戻ってしまう。
●再翻訳したら違う意味になる
ストール → (日英翻訳)→ Stall → (英日翻訳) → 失速 → (手動翻訳)→ 幅の広いマフラー
ストールは恐らくstoleのことで女性用の肩掛けのことを指すようだが、英語翻訳時にカタカナ語からだと誤訳してしまった。
●英日翻訳で和製英語が正しくなり再翻訳時に意味が変わる
マフラー → (日英翻訳)→ Scarf → (英日翻訳) → スカーフ → (手動翻訳)→ マフラー
マフラーはスカーフが正しい英語だけど日本語的には変
翻訳に使う辞書を抽出
自力で翻訳したものがある場合はそれを優先し、ない場合は再翻訳した値が元の用語と違うものを表示する、再翻訳した結果が元の用語と同じ場合はerrorの文字を出すようにややトリッキーな関数をセルに仕込んだ
=if(ISTEXT(F3),F3,if(E3 = FALSE,D3,"error"))
Pythonで集計した結果を処理したスプレッドシートのリンクはこちら
https://docs.google.com/spreadsheets/d/1t_qe7LOSiq_i4scZFeBmqHVKzRdFvkxdw79yhUNQHBQ/edit?usp=sharing
スプレッドシートの中身を一部切り出すとこのように、頻度と日英、英日の翻訳と自力で翻訳した単語があるのがわかるだろう

データ分析してわかったこと
日英再翻訳作戦が有効ではないものはこういうのが弱い
● 定着していない和製英語
リアルクローズ → (日英翻訳) → Real close ❌(clothにならない) → (英日翻訳) → リアルタイムに近いです ❌
たぶん普段着のことを言いたいのかな?アメリカのサイトでreal clothes で調べても汎用的な言葉としては出てこなかった
●記事に文字数制限されてるのかな?カタカナ語の略
ノースリ → (日英翻訳) → Nosuri ❌→ (英日翻訳) → Nosuri ❌
イメトレ → (日英翻訳) → Imetore ❌→ (英日翻訳) → Imetore ❌
●読者は漢字を読めないと思ってるのか?装飾用なのかな?無駄にカタカナにした単語
イッキ → (日英翻訳) → Ikki → (英日翻訳) → 一騎当千 ❌
アンバイ → (日英翻訳) → Systematics 🔺(体系的)→ (英日翻訳) → 按排 🔺(体系的の英語がどういうわけか塩梅の難しい方の漢字へ)
一方こちらは無駄なカタカナ化をいい感じに訳してくれている
イマドキ → (日英翻訳) → Nowadays⭕ → (英日翻訳) → 最近⭕
ポップさを演出したいのか日本語をカタカナにする傾向があるが、読み手の認知負荷を上げるだけで無駄だと思う。どこでライティングの勉強をしたのだろうか?心配になってきた。 アンバイなんて無理に使わずにもっと平易な言葉を使うのもライターの仕事じゃないだろうか?
スタイル、コーデ、テイスト問題
スタイルとコーデとテイストはほぼ同義で使われる。統一してもらいたい。 時にシルエットも同義で使われるが、本来の輪郭の意味のシルエットの場合もあるので注意が必要だ。
まとめ
ファッションサイトを読みづらいので、ファッション用語の辞書をファッションサイトをスクレイピングした結果から頻度を抽出して作成した。
当初はカタカナ語を日本語から英語へ翻訳し、英語から日本語へ再翻訳すれば解決するかと思いきや、敵は我々の想像よりも遥かに手強く、謎の和製英語や無駄に変に略したりと手動での翻訳を強いてきた。400以上の単語を手動で翻訳するもこちらが白旗を上げてしまう事態となった。ファッション業界の奥は深い。
chrome拡張でもHTMLの内容を更新してもボタンやタブのイベントがちゃんと動くようにする工夫をしている。これはまた別の記事にまとめる予定だ。普段ReactやVueだと気にしないけど、外部から既存のDOMをハックするには普段フレームワークを利用して使わないようなJSを使うことになりなかなか勉強になった。
今後の展開
大抵のサイトはそんなことはないが、本当に日本語が破綻している文をちらほら見かけることもあった。しかし画像が豊富だと文章はほぼ読まないから気にならないので問題がないのかもしれない。文字は飾りのようなものなのだろうか?ならば文字は全部Macのフォントに選択時に出てくる宮沢賢治のポラーノの広場でも違和感がないのかもしれない。新しい仮説が生まれてしまった。追って検証していく。
あのイーハトーヴォのすきとおった風、夏でも底に冷たさをもつ青いそら、うつくしい森で飾られたモリーオ市、郊外のぎらぎらひかる草の波。
ロケットビーバーイ!
Rubyで乱数のシードを設定しないでランダムな数値を取得できるかRubyのコードを調査した
概要
Rubyはなぜ乱数のシードを入れないで乱数を生成できるのかRubyの言語自体のソースコードを軽く読んで調査した。
乱数を生成するクラスは乱数のシードを引数に入れないと、乱数のシードを生成するメソッドを呼び出す、その乱数を生成するロジック内ではCPUクロック数やOSの乱数生成を呼び出して利用して乱数のシードを生成していた。
乱数のシードがUNIX timeだけに依存したりしていないので、高アクセスなサービスや並列化したバッチ処理などで同時刻に乱数を生成してもシード値が同じでバラけないってことはなさそうだ。
はじめに
Rubyのランダムな数値を生成する場合はこのような書き方をする。
r=Random.new r.rand(10) => 5 引数に整数を入れると0-9までのランダムな数値(Integer)を出力する 引数を少数を入れるとFloat型でランダムな数値を出力する r.rand(5.5) => 1.81617029321715
randメソッドの仕様
Method: Random.rand — Documentation for core (2.7.0)
Rubyで乱数を生成するは、擬似乱数列生成器にメルセンヌ・ツイスタを利用している。擬似乱数発生装置は乱数のシードと呼ばれる初期値が必要だ。(シードが不要な擬似乱数発生装置もあるかもしれないが今回の主題ではない)
コンパイラを利用するプログラミング言語では、乱数を生成する際には乱数のシードを用意するものが多くインタプリタの場合はRubyのように乱数のシードを使わなくても乱数を生成することができるものが多い印象がある。
Ruby以外の他の言語の乱数生成ロジック
乱数のシードが必要な例としてGo言語の場合
package main import ( "fmt" "math/rand" "time" ) func main() { rand.Seed(time.Now().Unix()) number:= rand.Int() fmt.Println(number) }
乱数のシードが不要な例としてJavaScriptの場合
const number = Math.random() console.log(number)
このJSのMath.random()の定義を見るとJavaScriptでは乱数のシードを入れられない逆にシードを入れさせないっていう仕様も珍しい
The implementation selects the initial seed to the random number generation algorithm; it cannot be chosen or reset by the user.
乱数のシードが不要な言語の場合、乱数のシードはどうしているのかRubyを例に調べてみる
Randomのコンストラクタの仕様を見ると Method: Random#initialize — Documentation for core (2.7.0)
Random.new_seedでランダムなシードの値を生成してインスタンス化しているしている。
Random.new_seedを実行してみるとこのような結果が返ってくる
Random.new_seed => 115032730400174366788466674494640623225
乱数のシード生成するのに乱数を生成している? ではその乱数を生成するシードはどう生成するというのだろうか?おそらく擬似乱数発生装置を利用しない方法で乱数を生成しているはずだ。
この対象のRubyのコード、Ruby本体のコードなのでC言語のコードで、Random.new_seedのコードは以下のように作られている。これを1行ずつ読み解く
Method: Random.new_seed — Documentation for core (2.7.0)
static VALUE random_seed(VALUE _) { VALUE v; uint32_t buf[DEFAULT_SEED_CNT+1]; fill_random_seed(buf, DEFAULT_SEED_CNT); v = make_seed_value(buf, DEFAULT_SEED_CNT); explicit_bzero(buf, DEFAULT_SEED_LEN); return v; }
1行目のVALUE v;は6行目return vで関数の返り値としているので生成されてたランダムな数値が格納される変数。
2行目uint32_t buf[DEFAULT_SEED_CNT+1];はDEFAULT_SEED_CNTより1大きいサイズの配列を宣言、固定値DEFAULT_SEED_CNTのサイズは4
3行目fill_random_seed(buf, DEFAULT_SEED_CNT);
fill_random_seedで乱数のシードを作るための乱数のシードを作ってる。
このメソッドのロジックをざっくり読むと配列のサイズ4のseedの各要素にfill_random_bytesでランダムなバイト数値を入れ、その上にCPU時間からナノ秒やマイクロ秒を取得してXORで上書きしている用に見える。
fill_random_bytesではちらっと見る限りLinuxのシステムコールで乱数を読んでるように見えが、今回は深追いしていない
static void fill_random_seed(uint32_t *seed, size_t cnt) { static int n = 0; #if defined HAVE_CLOCK_GETTIME struct timespec tv; #elif defined HAVE_GETTIMEOFDAY struct timeval tv; #endif size_t len = cnt * sizeof(*seed); memset(seed, 0, len); fill_random_bytes(seed, len, FALSE); #if defined HAVE_CLOCK_GETTIME clock_gettime(CLOCK_REALTIME, &tv); seed[0] ^= tv.tv_nsec; #elif defined HAVE_GETTIMEOFDAY gettimeofday(&tv, 0); seed[0] ^= tv.tv_usec; #endif seed[1] ^= (uint32_t)tv.tv_sec; #if SIZEOF_TIME_T > SIZEOF_INT seed[0] ^= (uint32_t)((time_t)tv.tv_sec >> SIZEOF_INT * CHAR_BIT); #endif seed[2] ^= getpid() ^ (n++ << 16); seed[3] ^= (uint32_t)(VALUE)&seed; #if SIZEOF_VOIDP > SIZEOF_INT seed[2] ^= (uint32_t)((VALUE)&seed >> SIZEOF_INT * CHAR_BIT); #endif }
4行目v = make_seed_value(buf, DEFAULT_SEED_CNT);でbufに格納されている乱数のシードから乱数を生成している
make_seed_valueではbufに入っている配列の数値をrb_integer_unpackで結合して乱数を生成していると思う。
static VALUE make_seed_value(uint32_t *ptr, size_t len) { VALUE seed; if (ptr[len-1] <= 1) { /* set leading-zero-guard */ ptr[len++] = 1; } seed = rb_integer_unpack(ptr, len, sizeof(uint32_t), 0, INTEGER_PACK_LSWORD_FIRST|INTEGER_PACK_NATIVE_BYTE_ORDER); return seed; }
上記のロジックをまとめると、random_seedのロジックは配列を用意して、その配列にCPU時間など使ってランダムな数値を格納したあとに、配列を結合して乱数のシードを作っていると言える
まとめ
「C」の茶の国から「T」の茶の国へと、本当に違う種類の国へ行くことができるのかデータ分析

イントロダクション
バックパッカーのバイブル沢木耕太郎の深夜特急で、ハナモチ氏という人物がお茶について語っているシーンが有る。
手元にある文庫版の第5巻を確認するとこんな一節である。
「彼らはTで始まるチャイを飲んでいる。でも、僕たちはCのチャイを飲んでいるのさ」
中略
私はトルコからギリシャに入ることで、アジアからヨーロッパへ、イスラム教圏からキリスト教圏へ、茶の国からコーヒーの国へ、「C」の茶の国から「T」の茶の国へと、違う種類の国へ来てしまっていたのだ。
というようにユーラシア大陸を東から西に行くとお茶の名前がChaからTeに変わるのだ。
北京語でお茶のことをチャーと発音するように、中国から陸路で伝わった茶はトルコまでCha系の発音で呼ばれることになる。
ではTeの方はというと、オランダがお茶を輸入した福建省あたりのビン南語ビン南語ではお茶のことをテーと発音するようで、そのオランダが海路で運んでいたため、オランダの植民地やヨーロッパ諸国ではお茶のことをティーやテーなどの発音表現する。
というわけでこのどこの国がCha系の国で、どこの国がTe系のなのか、テクノロジーを駆使して調べてみた。
調査方法
Googleスプレッドシートの翻訳関数
Googleスプレッドシートの関数に、GOOGLETRANSLATEというものがあり、日本語から英語へなど翻訳を行ってくれる。
例えばこんな風にセルにかいてあげると
=GOOGLETRANSLATE("tea","en","ja")
お茶と出力される
この関数の変数はそれぞれ
- 訳したい文字
- 翻訳元の言語2文字の略称
- 翻訳先の言語2文字の略称
となっている。つまり各言語のこの2文字のコードを片っ端から調べて、英語のteaから翻訳してやれば良いのだ。
この機能を知ったきっかけはサンミンさん@gijigaeのこのツイート
グーグルシートで簡単翻訳🇯🇵🇬🇧。スプレッドシートのセルに、関数を入れるだけです。入れるのはこんな関数。
— Sangmin @ChoimiraiSchool (@gijigae) 2019年4月2日
▼英語を日本語に訳す場合
=googletranslate(訳したいセル, "en", "ja")
▼日本語を英語に訳す場合
=googletranslate(訳したいセル, "ja", "en")
文章を訳すことも出来ます☝️。 pic.twitter.com/aysuzBAyVX
このツイートを見て各言語ごとにChaかTeか調べることができると思ったのがこの調査を始めたきっかけである。
ISO 639-1 言語を2文字表現
さきほどの2文字のコードは何かというと、国際規格のISO 639-1であるようだ。 このISO 639-1のリストをWikipediaから引っ張ってきた。
そして翻訳した結果はこちら docs.google.com
表の中で#VALUE! となっているのはGoogle翻訳が対応していない。すべてのISO 639-1で定義されている言語にGoogle翻訳は対応していないようだ。
この結果ISO 639-1の言語184言語中、101言語の翻訳できた。
というかGoogle翻訳って101言語対応してるの?すごない!!
ここまでの結果により翻訳に対応していない言語をフィルタリングできる。
Google翻訳ページ
Google翻訳のページでは、メジャーな言語はその翻訳とともに発音を再生してくれる機能が存在する。
またGoogle翻訳のページのURLは、ISO 639-1コードと翻訳したい文字をURLに含めることで動的に生成できる。
このようにセルを設定する
=concatenate("https://translate.google.com/?hl=ja&op=translate&sl=en&tl=", D77,"&text=tea")
するとGoogle翻訳のリンクを作ることができる
https://translate.google.com/?hl=ja&op=translate&sl=en&tl=ja&text=tea
forvo.com
forvo.comは各地の言語の単語の発音を登録できるサービスでありこちらもURLを動的に生成できる。
こちらもこのようにセルを設定する
=concatenate("https://forvo.com/word/",E77 ,"/#", D77)
するとforvo.comのリンクを作ることができる
https://forvo.com/word/お茶/#ja
それぞれの音声をすべて耳で聞いてChaかTeかを振り分け
それぞれの音声をGoogle翻訳で発音を再生できなかった場合はfevor.comで音声を確認した。 聞いた音声を元に下記のカラムを追加した。どちらにも音声がないものは今回は対象外とした。
- 聞いた音声にフリガナ
- ChaかTeかを分類
- 音声がチャに近い音で発音されるか、テに近い音で発音されるかそれぞれ分けた
- 話されている国をラベリング
- 各言語が話されている国がどこかを荒く調べて、それぞれ独立したデータとした
※ 話されている国のラベリングは、南北のアメリカ大陸で話される英語やスペイン語、ポルトガル語については茶の伝来について分布を見る際にノイズになるので英語はイギリス、スペイン語はスペイン語、ポルトガル語はポルトガルだけにしてある。
このあたりはデータ分析と言うよりは根性である。
振り分けした一例

結果
データを地図上にプロットすると以下のように、Chaの国、Teの国、 ChaでもTeでもないその他の国を作成した
Chaの国とTeの国
青がChaの国、赤がTeの国
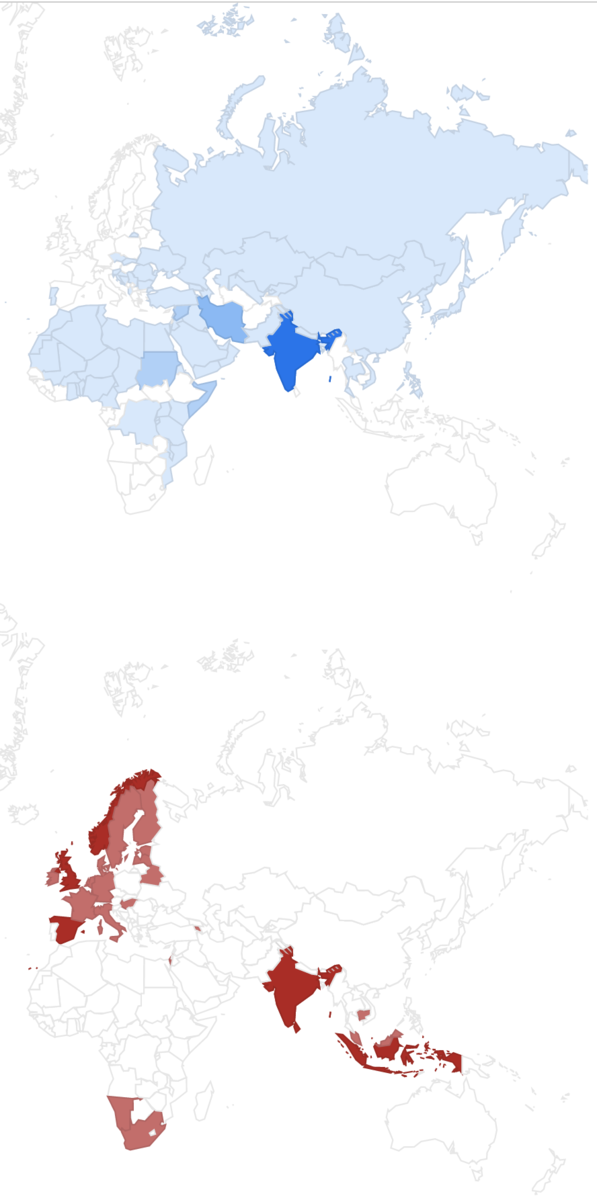
グラフの濃淡は、対象の言語の種類が複数あると濃くなる
ChaでもTeでもないその他の国

考察
ChaやTeについて
冒頭の深夜特急の引用文のように、トルコでChaの国が終わり、ギリシャからTeの国々になるのがデータをプロットした地図から分かる。
ヨーロッパはだいたいTe系統で、その他の国々はだいたいCha系統。
しかし東ヨーロッパの国々は結構Chaの国であった。これは意外でイメージだとギリシャでバッツリTeの国だと思っていた。
南インドやその近くのスリランカではなされるタミル語はお茶のことをテニーと発音し、インドはChaの国でありTeの国でもあることがわかった。
Teの国は海路で茶が伝わったとされるが、インドネシアや、南アフリカ、ナミビアはかつてオランダの植民地だった影響でTeの国なのだと思われる。先程のタミル語が話されるスリランカもオランダの植民地だったのでTeの国であるのだろう。
Teの国だと思っていたヨーロッパの中でもポルトガルはChaの国
ポルトガル語はChaの国でお茶のことをチャと発音する。
ポルトガルは植民地のマカオから茶を輸入していたので、広東語の茶とおそらく同じ音で伝わったものだと思われる。 (これは友達の @Y_Hirano が教えてくれた。多謝)
ウィキペディアの茶の項目にも書かれている(出典は無いが) ja.wikipedia.org
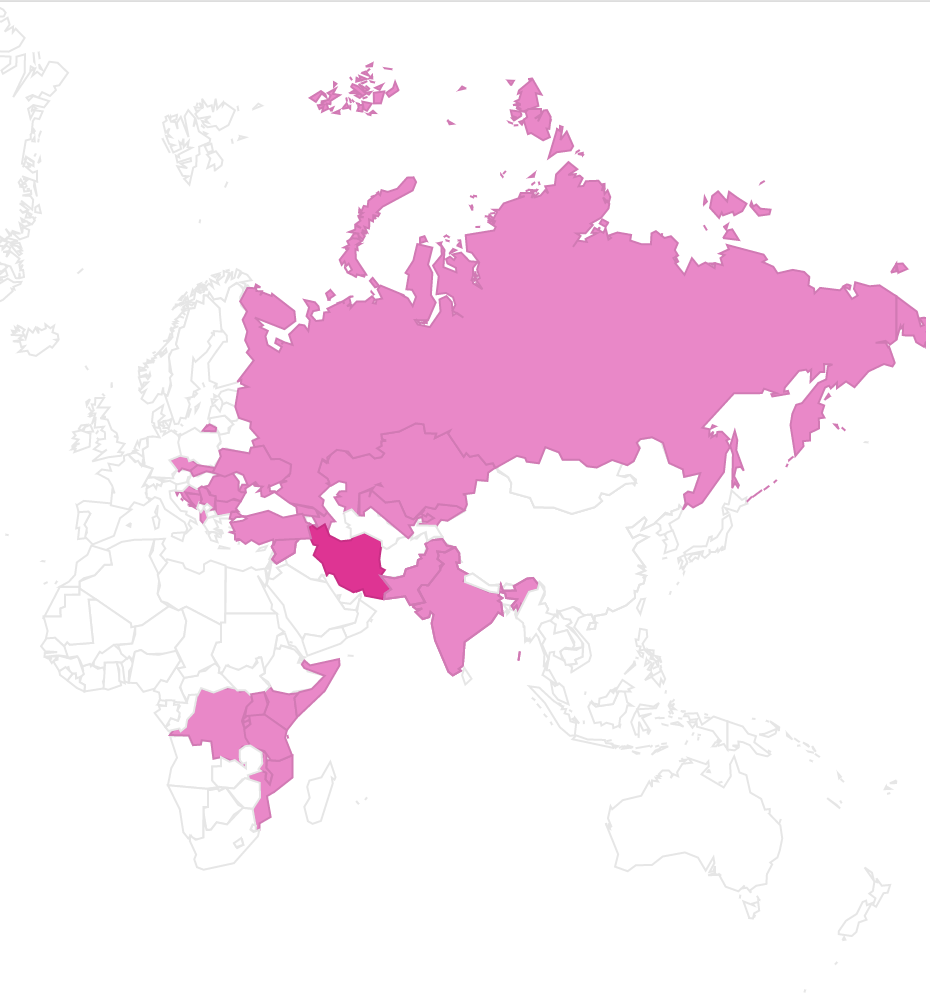
Chaの国で話されるお茶の発音は大体チャイ
各言語の音を直接自分の耳で聞いてフリガナを振っていくと、Chaの国86ヶ国中、32ヶ国がチャイと発音し37%の国がお茶のことをチャイと発音する。
特に東西問わずアジア圏でチャイが多く、アジアのカフェやレストランではチャイと言うとお茶が出てくる可能性が高いのでぜひチャレンジしてみてほしい。
お茶をチャイと発音する国一覧
ChaでもTeでもない国が存在する
ChaでもTeでもない国がいくつかあった。
ポーランド語はのお茶を表すherbata(ハルバータ)はラテン語herba theaが語源らしい herbata - ウィクショナリー日本語版
そのラテン語herba theaはそれぞれ
- heabaが草 herba - Wiktionary
- theaが茶 thea - Wiktionary
リトアニア語のお茶を表すarbata(アルバータ)はリトアニアはポーランドに隣接しているので文化圏が近いためポーランド語がなまったものだと思われる。
ソマリア語のお茶を表すshaahはfevor.comにもGoogle翻訳にも存在しなかったので特別にyoutubeで検索してみるとソマリア語で喋っている動画にshaahを発音しているものを見つけた。
https://www.youtube.com/watch?v=BAAt03W2z7g , https://www.youtube.com/watch?v=1lz87j-pKwM
これら2つの動画からどうやらshaahはシャーと発音するらしい。
今回はアラビア語の茶、”シャーイ”はChaの国と分けている。字面で見るとChaじゃないじゃないかと思うだろうが、音を聞くとTeかChaかどちらかで分類するとCha寄りだと判断した。
アラビア語のシャーイがなまってソマリア語はシャーであろう。広義の意味ではChaの国としても良いかも知れない。
その他、今回の調査でわかったこと
- アラビア語が話される国がたくさんある。英語、中国語、スペイン語は世界の話させている人口カバー率が高いが、アラビア語はその次ぐらいだろうか
- Google翻訳はインドの方言がたくさん対応している
- Google翻訳は英語、ウェールズ語、アイルランド語、スコットランド語とイギリスの4つの国の言語に対応している
- Google翻訳が対応している言語は、話される人口が数千万人以上いる言語と仮定すると、インドやインドネシアの言葉が多く対応されれているのもの納得である
- というかGoogle翻訳すごない?
じゃーねー。ロケットビーバーイ